SoC 2008/x264/Speed Optimizations
This project is part of Google Summer of Code 2008.
|
Contents
Project Abstract
My goal is to search for speed optimizations in x264 (and, time allowing or if anything seems an obvious port, possibly a bit in vlc and ffmpeg as well). I intend to thouroughly profile the thing and find out where we might do better.
Implementation
Will be mainly on a day to day basis - find something, see if something can be done about it. My main development system so far was an Athlon X2 3800+, so I mainly did 64bit and MMX, some SSE code so far, but it recently lost its case to a new and shiny Q9300 (will be back in service once that case arrives - seems it may take a while). I intend to be learning a lot of SSSE3 and SSE4.1 and will hopefully find some uses for it.
Current Status
Battling with Hardware. Fedora 9 is said to have the latest and greatest of all distributions in regard to supporting the Intel Onboard-Graphics (it's just a little bit behind on the version number and i think most of the newer stuff is already in). However, my G35 mobo does not really like me yet. Some things still to be found out. Expect me to rant a bit on the channel if it was just another really bad day.
Other than that, I hope to get into vtune next week, maybe even try to get the free IDA going somehow. And then we'll see where that gets me.
Week 1
Downloaded free IDA 4.9 and demo version of 5.2. The free version works surprisingly well in current wine. Just some font problems (fixed by selecting another one) and window handling is a bit awkward sometimes. Successfully disassembled some linux programs. Unfortunately the free version doesn't do 64 bit code and newer SSE, and the demo is severely limited in other aspects (no saves, time limit per session).
But then again, so far good old objconv -fasm worked well enough, too. So IDA should be nice to have if needed.
Registered with Intel for non-commercial downloads and got Intel Compiler Collection, Performance Primitives and of course vtune, but vtune officially only supports Fedora up to 7 (and with stock kernel) currently. Will have to fiddle a bit with that in the next days (given the X problems I had even with the current driver, downgrading to 7 is probably not even an option).
Found out about liboil and checked their zigzag implementation. They have an altivec zigzag, but it doesn't look like their idea can be borrowed - ends with a lot of fixup in c. But I think checking there for other ideas cannot hurt. Will keep a copy.
Hardware troubles turned out to be partly hardware, partly software related. Both 4 GB kits have been faulty (either A-Data Vitesta wasn't the best brand to buy or it was just my sheer luck again that both gave errors in memtest86). Returned them, hope the vendor is going to refund the money soon. Running on the 4x1 GB from my previous system for the time being. X currently only works with uncached video memory. Shouldn't affect the encoding measurements, however I noted that h264 playback becomes very jerky with uncached memory. Fedora already has an open bug for the issue - let's hope it can be resolved soon.
In related news: Finished term project paper at least so far that I could present it to my professor. Had minor comments, going to hand it in by Jun 6.
Week 2
Was pretty tied up with finishing my term paper, so no real work on GSoC happened. Things i still managed to do:
Looked into SSEPlus.
Fiddled around with vtune a bit more. Sampling driver doesn't even compile with current kernels and doesn't look like it's easily fixed. The Support Forum seems to indicate people are even having problems after downgrading to the supported kernel on unsupported (newer) Fedora Releases like F8. Response was "not in the list of supported OS, wait for next release". I don't want to waste time fixing bugs in their proprietary software. This will probably mean waiting for the next vtune or preparing a test partition with the supposedly supported F7. For now, oprofile it is.
Had a couple test runs of pengvados SSE4-mubench on my system. Short run got a couple errors, but at least results, long run bombs. My perl is next to non-existent, so I'll have to hope for pengvado or AI4 to fix this.
Got git running the way I want (follow master from x264.git instead of the not updating master in the private repo). Turns out the easy way to do this seems to be:
git remote add x264 git://git.videolan.org/x264.git
and than change "remote = origin" to "remote = x264" for the master branch in .git/config. Did a test push after pulling, which successfully updated the master branch in my private repo, so i think it works the way I want.
Pushed the rest to
Week 3
Some initial profiling next. Dark_Shikari suggested using his Black Pearl clip for that. Open to suggestions for suitable HD material. Going to use Elephants Dream if nothing better comes up. Will also try to find out if there are notable differences with interlaced material (will use DVB-S captures for that, probably a bit of Torchwood).
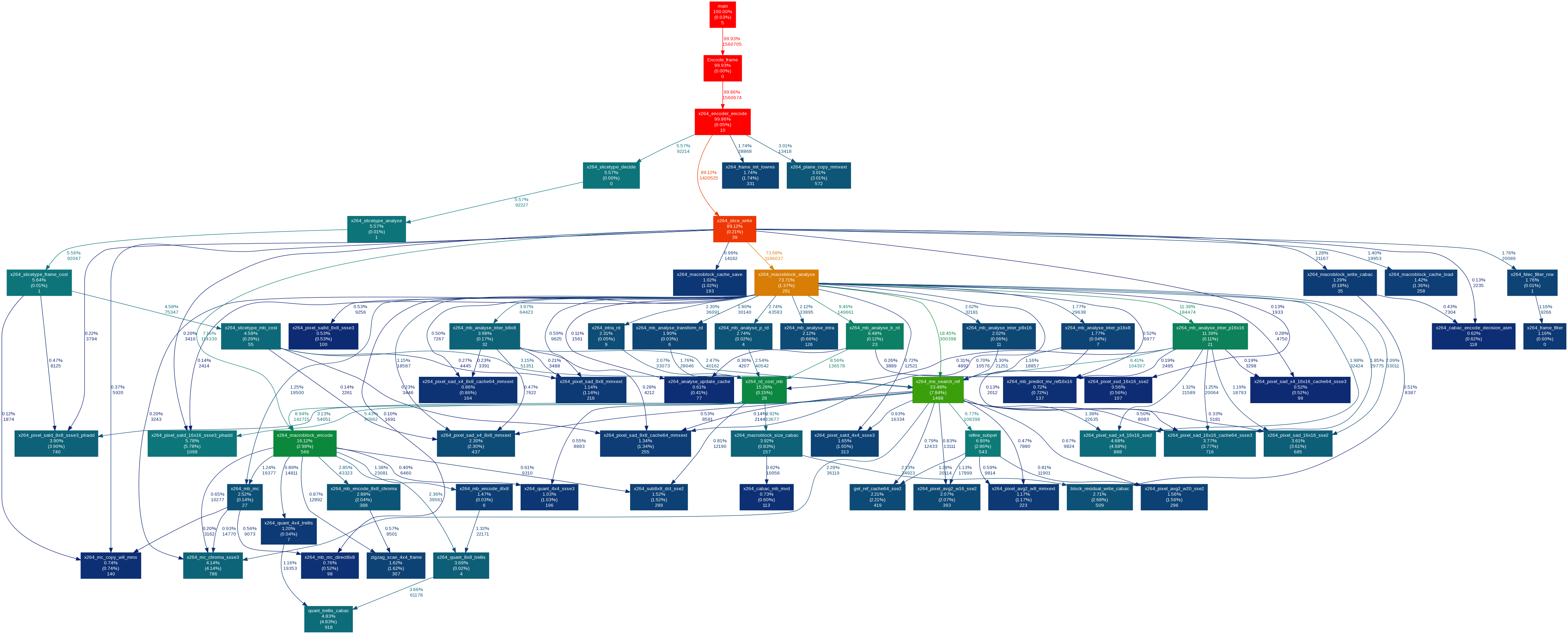
Ran the profiles (used a sequence of BBB instead of ED). Found a version of gprof2dot that groks oprofile output, managed to get it to work. Produces pretty graphs Media:Oprofile-graph.png, but due to the way call graph profiling in oprofile works, not all cycles are necessarily attributed correctly. Need to find out if gprof is better suited to that.
{kind=link}
Week 4
Revisited the zigzag functions. The 8x8 SSE2 performs nicely on my Penryn (cuts runtime from ~97 cycles to ~47), the 4x4 seems to cut ~27 cycles to ~10. (however, I do not know if I can trust the C cycle counts - they used to be lower when we first benched this).
Took a look at pengvados last set of profiles (generated using different settings and on a larger encode), found out that at higher settings satd, sa8d and dct/idct show up high enough to warrant some optimizing. Found out that they could be made faster (around 3%) by doing SUMSUB differently (two paddw and one psubw cannot run in one cycle - now it has a mov, a sub and an add and those do seem to run in less. The mov probably can't pair with the following sub/add due to data dependency, but it seems those can pair with the _next_ mov).
But with the current code organization, each file has its own set of helper macros. Some refactoring would probably be useful before doing this change.
Week 5
Pengvado gave his ok for a bit of refactoring, so that's going to happen soon.
This week saw a rather complicated birth of x264_predict_8x8_filter_mmxext. Making it faster than the existing c function for all cases turned out to be a bit harder than expected. In the end, I decided to make the common case as fast as possible (nearly 50% down on my system) and to take the branching approach for the not so common cases (all of them faster now, but sometimes just a cycle or two). Also, had to hack checkasm a bit to bench it at all. In the end, I succeeded. Doesn't use palignr yet, so it's likely to get a ssse3 brother soon. Including the call to it will need a bit more code changes. The current pointer arrays for the asm predict functions need to be changed to the struct approach that's already used elsewhere.
Week 6 / 7
Bit of refactoring, ssse3 version of filter, quali zigzags and sse2 zigzag for penryn finally went into git. Latter one a) shows that core insn reordering doesn't handle _all_ cases ok (manual helped here), and b) needs the fast unpacker of penryn to perform, pengvado suggested we're likely going to have some SHUFFLE_IS_FAST capability that could depend on. Refactoring only has basic stuff for now (shared macros moved to common file, couple micro optimization). Once that's in, I'm going to refactor a bit further in smaller patches (TRANSPOSE and HADAMARD seem obvious candidates (but implementations turned out to be _just_ a little different from each other), also PALIGNR as that's now also used in predict). Some speed gains (i.e. the p4 hurting SUMSUB_BA mov trick for core) still missing too. More predict changes coming up next (i hope the fast penryn unpack is going to help the predicts not in asm yet).
Week 8
Mainly spent on optimizing predict-a.asm (and the fun debugging that came with that).
Week 9
Finally got predict-a.asm working on wednesday, entirely SIMDd now. Some prettyfication and macroing still needed, also one or two sse2 functions still missing. Rest of the week went mostly into optimizing hpel_filter_h_ssse3 from mc-a2.asm. Wasn't very successful at first (unaligned 64bit loads that _don't_ cross a cacheline aren't that expensive), finally found the trick after a day or two of experimenting. Minor optimizations went into hpel_filter_v (kill useless prefetch, don't mix temporal and non-temporal). End result is a relatively small patch (already in my repo), but it manages to bring hpel_filter_ssse3 down to ~30500 (from 36500) on my system. 16.5% faster ;)
Schedule
Had a presentation on May 23rd (yeah, just the right time to buy and install new hardware). Will need to hand in the write up for all of it soonish. After that, mainly weather dependent. Cold heads code, hot heads need to be near (preferably cold) water. Well. Wasn't coding what nights were made for?
Been to my professors office hour Jun 2. Paper on the presentation (or rather, the term project presented) due Jun 6. Right in time for Euro 2008 ;) No, honestly: After that, mostly clear skies ahead time-wise. (Except maybe a bit of footy plus poker every now and then. Let's see how Germany does :)
(edit Jun 29: Euro 2008 is over. Germany lost the final 0-1 to Spain. Well, back to business :)
Other probable time constraints: Will have to juggle a bit between doing things for GSoC and thinking (and writing) about these things for my Thesis. Switching sometimes should help keep up motivation (and idea flow) for the other. Otherwise, nothing largish. Maybe a weekend trip or two, but nothing long lasting.
May 31/Jun 1: Visit family. (Nice visit. Sister dropped by on her trip back from UK to Australia, and saw my oldest aunt again after >8 years. Sunny weather, unusually hot for the time of year. Usually, we only see >30C in August, if at all. Hope it'll get a bit colder soon.)